SPUFI - SQL processor using file input facility
SPUFI is intended primarily for application programmers who wish to test the SQL portions of their programs or administrators who wish to perform SQL operations.
SPUFI reads SQL statements contained as text in a sequential file or in a member of a PDS, processes those statements and places the results in an ISPF browse session. By specifying the input and output data sets and selecting the appropriate options, we can execute SQL statements in an online mode.
Steps to execute SQL by using SPUFI:
-
Open SPUFI and specify the initial options.
-
Optional: Changing SPUFI defaults.
-
Enter SQL statements in SPUFI.
-
Process SQL statements with SPUFI.
Step 1: To open SPUFI and specify initial options
1. Select SPUFI from the DB2I Primary Option Menu as shown in The DB2I primary option menu. The SPUFI panel is displayed.
2. Specify the input data set name and output data set name. An example of a SPUFI panel in which an input data set and output data set have been specified is shown in the following figure.
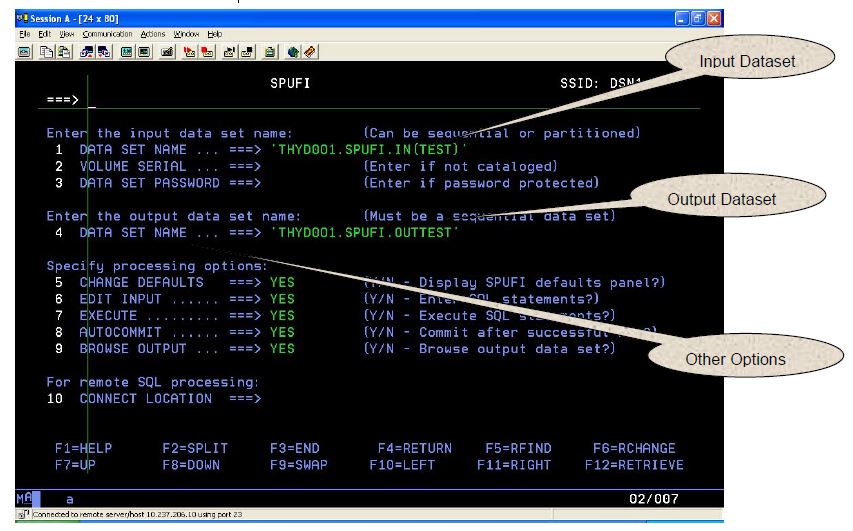
You need to enter Input data set name and Output data set name.
Input Data Set:
Input dataset must be allocated before invoking SPUFI. This can be a member of Partitioned Data Set or a Sequential Data Set. This can be empty and can be edited as part of the SPUFI session.
It is recommended to maintain a partitioned data set to keep track of SQL statements used. Input dataset can be defined as a fixed, blocked data set with an LRECL of 80.
Output Data Set:
The output data set need not be allocated before using SPUFI. If the output data set does not exist, SPUFI creates a virtual, blocked sequential data set with an LRECL of 4092.
Step 2: Optional- Specify new values in any of the other fields on the SPUFI panel
After entering Input data set name and Output data set name, we need to specify following options.
CHANGE DEFAULTS: When Y is specified, the SPUFI defaults panel appears as follows:
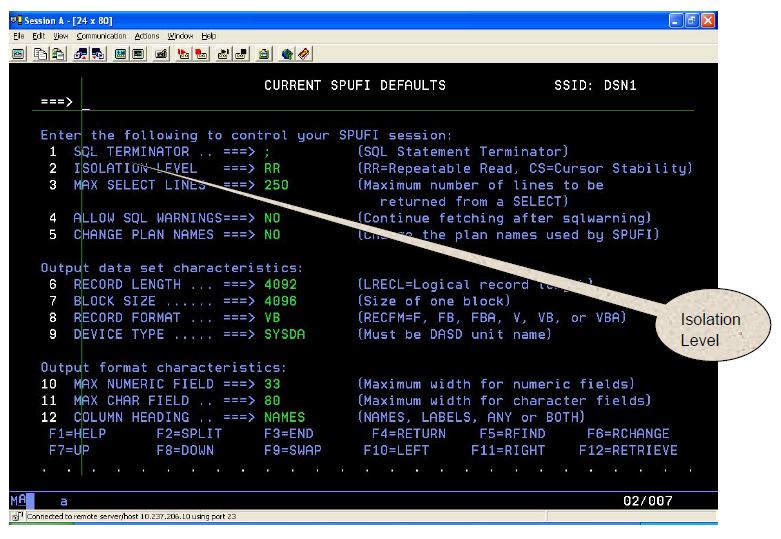
Options of “CURRENT SPUFI DEFAULTS”:
-
Typically, defaults are changed only once—the first time someone uses SPUFI. ISPF saves the defaults entered from session to session.
-
Be sure to specify the following defaults:
Isolation Level: Always set this option to CS (Cursor Stability).
(Note: You will study about Isolation Level in detail in your forthcoming sessions.)
Max Select Lines: Set to an appropriate number. If we will be selecting from large tables that return more than 250 rows, the installation default value of 250 is insufficient. SPUFI stops returning rows after reaching the specified limit, and it issues a message indicating so.
-
All the remaining installation defaults are appropriate. So keep them as they are.
-
EXECUTE: When Y is specified, the SQL in the input file is read and executed.
-
AUTOCOMMIT: When Y is specified, a COMMIT is issued automatically after the successful execution of the SQL in the input file.
When you specify N, SPUFI prompts you about whether a COMMIT should be issued. If the COMMIT is not issued, all changes are rolled back.
Note: You will study about commit and rollback in our forthcoming sessions.
-
BROWSE OUTPUT: When Y is specified, SPUFI places you in an ISPF browse session for the output data set. You can view the results of the SQL that was executed.
Note: Specifying Y for all these options (from 6 to 9) except Change Defaults (5) is common.
Step 3: Enter SQL statements in SPUFI.
SQL statements can be written in all but the last 8 bytes of each input record; this area is reserved for sequence numbers. This can contain multiple SQL statements, as long as they are separated by semicolons. Comments are preceded by two hyphens. If the input file contains multiple SQL statements, SPUFI will stop execution of those statements as soon as it encounters an error in any one of them.
Sample SQL statements in the input data set as follows:
--DELETE FROM THYD001.TEST --WHERE TEST_NO = 'A114'; -- SELECT * FROM THYD001.TEST; -- |
Step 4: Process SQL statements with SPUFI
-
On the SPUFI panel, specify YES in the EXECUTE field.
-
If you did not just finish using the EDIT panel to edit the input data set as described in "Entering SQL statements in SPUFI," specify NO In the EDIT INPUT field.
-
Press Enter.
SPUFI passes the input data set to DB2 for processing. DB2 executes the SQL statement in the input data set and sends the output to the output data set.
When the SQL is executed and browsed, an output data set like the following appears:
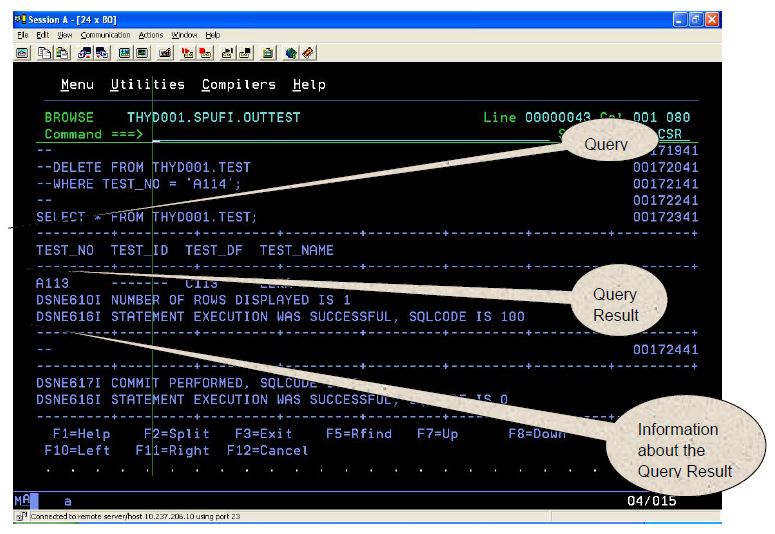
The output file will contain a sequence of results, one for each statement (including the relevant SQLCODE), followed by a summary of the overall execution (including, in particular, an indication as to which of Commit and Roll Back occurred). There are some specific defaults to be set for Output data set.
If you have any doubts or queries related to this chapter, get them clarified from our Mainframe experts on ibmmainframer Community!
Are you looking for Job Change? Job Portal